Training a fastai Image Classification Model to Identify Japanese Food
Introduction
Lesson 1 in the fastai Practical Deep Learning for Coders course goes through using the fastai package to train a “forest or bird” classifier. In this TIL post I’ll go through the code to create a multi-class dataset (30 classes, but could be more or less), train a classification model and perform inference. In a future post I’ll go through how to host the inference model with gradio on Huggingface Spaces.
Jeremy Howard has a great jupyter notebook on Kaggle which concisely creates a two-class dataset and trains a classification model. The following code expands on this with custom helper functions for download_dataset, download_single_image, inference_new_image, plot_cat_probabilities and delete_images. The repo is available at seamusbarnes/japanese-food-classifier.
Code
# import from basic packages
import importlib
from fastai.vision.all import *
from fastai.learner import load_learner
# Import our helper functions
from utils import (
delete_images,
download_single_image,
download_dataset,
inference_new_image,
plot_cat_probabilities
)
# delete any old images at the top level
extensions = ['jpg', 'JPG', 'jpeg', 'png', 'webp', 'jpg!d', 'ashx', 'gif']
delete_images(extensions, depth=1, verbose=False)
# download a test image to confirm everything works
dest = download_single_image('cat')
delete_images(extensions, depth=1, verbose=False)
# define search terms
terms = ['sushi', 'udon', 'tofu', 'tempura', 'yakitori', 'sashimi', 'ramen', 'donburi', 'natto', 'oden', 'tamagoyaki', 'soba', 'tonkatsu', 'kashi pan', 'sukiyaki', 'miso soup', 'okonomiyaki', 'mentaiko', 'nikujaga', 'curry rice', 'unagi no kabayaki', 'shabu shabu hot pot', 'onigiri', 'gyoza', 'takoyaki', 'kaiseki ryori', 'edamame', 'yakisoba', 'chawanmushi', 'wagashi']
# build a datablock and dataloader
blocks = DataBlock(
blocks=(ImageBlock, CategoryBlock),
splitter=RandomSplitter(valid_pct=0.2),
get_y=parent_label,
get_items=get_image_files,
item_tfms=[Resize(192, method='squish')],
batch_tfms=[
Flip(), # Random horizontal flip
Rotate(max_deg=10), # Small rotation (up to 10 degrees)
Zoom(max_zoom=1.1), # Slight zoom (up to 10%)
Brightness(max_lighting=0.2), # Adjust brightness
Contrast(max_lighting=0.2) # Adjust contrast
# Warp(magnitude=0.1), # Minimal warping for perspective
]
)
dls = blocks.dataloaders(dataset_path)
# look at a few exa,examples
dls.show_batch(max_n=10)
# create a learer and train
learn = vision_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(5)
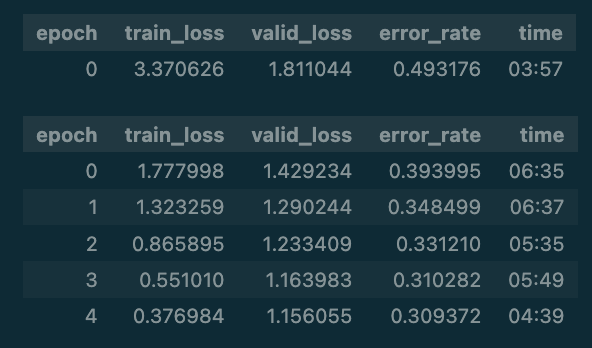
As you can see, fine-tuning resnet on only 3000 images takes 6 minutes per epoch, over 30 minutes in total! This is because I naively fine-tuned this model on my Macbook M2, which doesn’t have a GPU and even though it has some fancy Apple Silicon parallel processing hardware, fastai doesn’t recognise it or use it. I’m sure if I re-ran this on Kaggle or Paperspace with a dedicated GPU it would be much faster (maybe x5 or x10 times faster). But it still trained, so let’s test the model with a new image. I’ve downloaded a new image with a new search term to see if the model can generatlise beyond the original dataset, but I can’t be sure atm (I could have separated the datasets into train and test but didn’t bother for this simple example, this is bad practice on my part!).
# run an inference example on a new image (no guarantee it's not in the training set
term = 'california roll'
cat, cat_idx, probs = inference_new_image(term, learn, display_result=True)
print(f"Type of 'probs': {type(probs)}")

That looks like sushi to me! Let’s plot the probabilities of each class.
# plot predicted probabilities
plot_cat_probabilities(probs, learn)
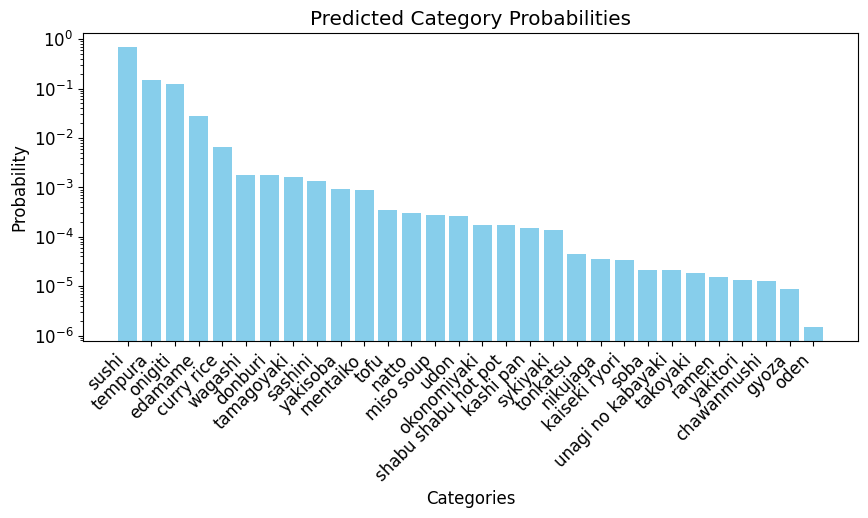
So the model thinks there’s a 76.01% chance the image is of sushi, an approximately 13% chance it’s tempura, and then the rest of the classes drop off exponentially.
We can also save the model as a .pkl file for later use, or uploading to an inference-only application (I will write about how I hosted the inference model on Huggingface Spaces later). You can also import this model if you don’t want to train the model each time you start up the notebook (this line is out-of-order of course).
# export the model to a .pkl file
learn.export(fname='model_2025_01_19_japanese-food_01.pkl')
# import the model
learn = load_learner('model_2025_01_19_japanese-food_01.pkl')
And that’s it! A simple way to create your own extensive dataset and train a multi-class model.
Appendix: The utils.py File with Helper Functions
Here is the utils.py file with the required helper function.
import os
import subprocess
from fastbook import search_images_ddg, download_url
from fastai.vision.utils import download_images, verify_images, get_image_files, resize_images
from fastai.vision.all import Image
from pathlib import Path
from datetime import datetime
import matplotlib.pyplot as plt
def delete_images(extensions, depth=1, verbose=True):
"""
Deletes files with the given extensions up to a certain max depth from the current folder.
Args:
extensions (list): List of file extensions to delete (e.g. ['jpg', 'png', 'gif']).
depth (int): Maximum recursion depth for searching files.
"""
for ext in extensions:
command = ['find', '.', '-maxdepth', str(depth), '-type', 'f', '-name', f"*.{ext}", '-delete']
try:
subprocess.run(command, check=True)
if verbose:
print(f"Deleted all .{ext} files in depth {depth}")
except subprocess.CalledProcessError as e:
print(f"Error: {e}")
def download_single_image(term, attempts=10, view=True):
"""
Searches DuckDuckGo for images matching 'term' and downloads the first image that works.
Args:
term (str): Search term (e.g. 'cat').
attempts (int): Number of download attempts before giving up.
view (bool): If True, displays the downloaded image as a thumbnail.
Returns:
dest (str): Path to the downloaded image.
"""
dest = f'{term}.jpg'
urls = search_images_ddg(term, max_images=10)
for i in range(attempts):
try:
download_url(urls[i], dest, show_progress=False)
if view:
image = Image.open(dest)
# image.show()
display(image.to_thumb(256, 256))
break
except Exception as e:
print(f'Error on attempt {i+1}: {e}')
return dest
def download_dataset(terms, subfolder, n_images=200, force=False, verbose=True):
"""
Creates a dataset by searching DuckDuckGo for a list of terms and downloading
images for each term. Images are resized, and any corrupted images are removed.
Args:
terms (list): List of search terms (e.g. ['sushi', 'ramen']).
subfolder (str): Name of subfolder where images will be saved.
n_images (int): Number of images to attempt to download for each search term.
force (bool): If False, does not download again if the path already exists.
verbose (bool): Print progress if True.
Returns:
path (Path): Path to the folder containing the downloaded images.
"""
path = Path(os.path.join('datasets', subfolder))
if path.exists() and not force:
return path
for term in terms:
t0 = datetime.now()
dest = path/term
dest.mkdir(exist_ok=True, parents=True)
urls = search_images_ddg(term, max_images=n_images)
download_images(dest, urls=urls[:])
resize_images(dest, max_size=400, dest=dest)
t1 = datetime.now()
if verbose:
print(f'{term} images downloaded in {(t1 - t0).total_seconds():.2f} s')
failed = verify_images(get_image_files(path))
failed.map(Path.unlink)
return path
def inference_new_image(term, learner, display_result=True):
"""
Downloads a new image by searching DuckDuckGo for 'term' and uses the given
learner to make a prediction.
Args:
term (str): Search term to find an image for inference.
learner (Learner): A trained fastai learner.
display_result (bool): If True, displays the image and prints the prediction.
Returns:
cat (str): Predicted category.
cat_idx (int): Index of the predicted category in the probability tensor.
probs (Tensor): Probability tensor for all categories.
"""
image_dest = download_single_image(term, view=False)
cat, cat_idx, probs = learner.predict(image_dest)
if display_result:
img = Image.open(image_dest)
img.show()
display(img.to_thumb(256, 256))
print(f'Category: {cat}; Prob: {probs[cat_idx]*100:.2f}%')
return cat, cat_idx, probs
def plot_cat_probabilities(probs, learner):
"""
Plots a bar chart of all categories vs. the probability predicted by the model.
Args:
probs (Tensor): Probability tensor of shape (n_categories,).
learner (Learner): Trained fastai learner, used to fetch category names.
"""
categories = learner.dls.vocab
sorted_indices = sorted(range(len(probs)), key=lambda x: probs[x], reverse=True)
sorted_categories = [categories[idx] for idx in sorted_indices]
sorted_probs = [probs[idx].item() for idx in sorted_indices]
plt.figure(figsize=(10, 8))
plt.bar(sorted_categories, sorted_probs, color='skyblue')
plt.xlabel('Categories')
plt.ylabel('Probability')
plt.title('Predicted Category Probabilities')
plt.xticks(rotation=45, ha="right")
plt.show()