How to Use the OpenAI API
It is very easy to use the OpenAI Python API to have chat comversations with their available models. I wrote some scripts that enable the user to have a back and forth conversation with any of the API available models in the terminal. You can also print the entire conversation logs, view the logs in a log.txt file, and track the cost of the conversation. Here is an example:
Example of a back and forth conversation in the terminal
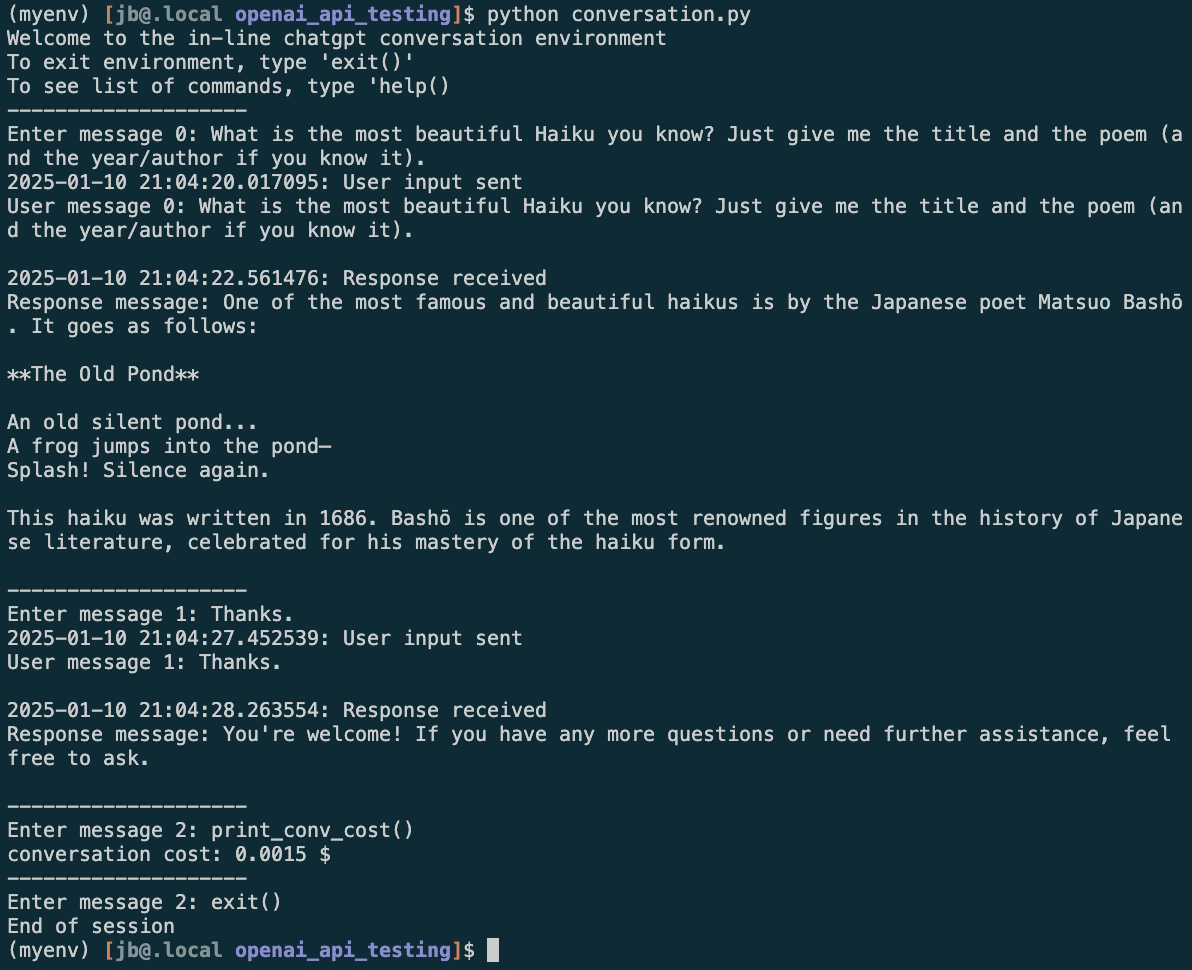
I uploaded the code for the conversation repo seamusbarnes/openai_api_testing. When you run the terminal command python conversation.py the an OpenAI() client is generated and the user is prompted to provide an input message. If the input message is not one of the “help” functions (exit(), help(), print_conv_logs(), print_conv_cost()) that message is appended is appended to the messages log (with alternating user, assistant messages) and then the messages log is passed to the client. The response is printed and the messages are logged. These logs are continually added to a log_file which by default is stored in /data/log.txt. The full code is as follows:
# conversation.py
import os
from openai import OpenAI
from datetime import datetime
from utils_response import *
import os
import json
def api_conversation(
message,
messages=None,
client=None,
model='gpt-4o',
system_prompt='You are a helpful assistant.',
max_tokens=None,
temperature=None):
if not client:
client = OpenAI()
if not messages:
messages = [{
'role': 'system',
'content': system_prompt
}]
messages.append({
'role': 'user',
'content': message
})
t0 = datetime.now()
response = client.chat.completions.create(
model=model,
messages=messages,
n=1,
max_tokens=max_tokens,
response_format={'type': 'text'},
temperature=temperature
)
t1 = datetime.now()
messages.append({
'role': 'assistant',
'content': get_response_content(response)
})
return response, messages, t0, t1
def log_interaction(
response,
messages,
t0,
t1,
new_chat,
data_path='data/',
log_file='log.txt'):
model, tokens, cost = get_response_metadata(response)
response_message = get_response_content(response)
response_time = (t1 - t0).total_seconds()
timestamp_call_str = t0.strftime('%Y-%m-%d %H:%M:%S')
timestamp_response_str = t1.strftime('%Y-%m-%d %H:%M:%S')
metadata = {"new_chat": new_chat,
"timestamp_call": timestamp_call_str,
"timestamp_response": timestamp_response_str,
"input_tokens": tokens[0],
"output_tokens": tokens[1],
"total_tokens": sum(tokens),
"message": messages,
"most_recent_response": response_message,
"model": model,
"cost ($)": f'{cost:.4f}',
"response_time (s)": response_time, # Example response time in seconds
}
# Create the directory if it does not exist
os.makedirs(data_path, exist_ok=True)
with open(os.path.join(data_path, log_file), 'a') as file:
json.dump(metadata, file, indent=4)
file.write('\n')
return
def main():
print("Welcome to the in-line chatgpt conversation environment")
print("To exit environment, type 'exit()'")
print("To see list of commands, type 'help()")
client = OpenAI()
message_count = 0
cost = 0
initial = True
while True:
print('--------------------')
user_input = input(f"Enter message {message_count}: ")
if user_input.lower() == 'exit()':
print("End of session")
break
if user_input.lower() == 'help()':
print("Available commands:")
print("exit(): exits conversation")
print("help(): displays this help message")
print("print_conv_logs(): prints conversation history")
print("print_conv_cost(): prints conversation total cost")
continue
if user_input.lower() == 'print_conv_logs()':
try:
for msg in messages:
print(msg)
except UnboundLocalError as e:
print(f'UnboundLocalError: cannot print conv logs before conversation has started')
continue
if user_input.lower() == 'print_conv_cost()':
print(f'conversation cost: {cost:.4f} $')
continue
print(f'{datetime.now()}: User input sent')
print(f'User message {message_count}: {user_input}')
if initial:
response, messages, t0, t1 = api_conversation(
message=user_input,
messages=None
)
else:
response, messages, t0, t1 = api_conversation(
message=user_input,
messages=messages
)
log_interaction(
response,
messages,
t0,
t1,
initial
)
initial = False
response_message = get_response_content(response)
cost += get_response_cost(response)
print(' ')
print(f'{datetime.now()}: Response received')
print(f'Response message: {response_message}')
print(' ')
message_count += 1
if __name__ == "__main__":
main()
# utils_response.py
def get_response_cost(response):
pricing_units = 1e6
pricing = {'gpt-4o': (5.0, 15.0),
'gpt-4o-2024-08-06': (2.5, 10.0),
'gpt-4o-2024-05-13': (5.0, 15.0),
'gpt-4o-mini': (0.150, 0.600),
'gpt-4o-mini-2024-07-18': (0.150, 0.600),
'chatgpt-4o-latest': (5.00, 15.00),
'gpt-4-turbo': (10.00, 30.00),
'gpt-4-turbo-2024-04-09': (10.00, 30.00),
'gpt-4': (30.00, 60.00),
'gpt-4-32k': (60.00, 120.00),
'gpt-4-0125-preview': (10.00, 30.00),
'gpt-4-1106-preview': (10.00, 30.00),
'gpt-4-vision-preview': (10.00, 30.00),
'gpt-3.5-turbo-0125': (0.50, 1.50),
'gpt-3.5-turbo-instruct': (1.50, 2.00),
'gpt-3.5-turbo-1106': (1.00, 2.00),
'gpt-3.5-turbo-0613': (1.50, 2.00),
'gpt-3.5-turbo-16k-0613': (3.00, 4.00),
'gpt-3.5-turbo-0301': (1.50, 2.00),
'davinci-002': (2.00, 2.00),
'babbage-002': (0.40, 0.40)
}
model = get_response_model(response)
input_tokens, output_tokens = get_response_tokens(response)
input_rate, output_rate = pricing[model]
input_cost = (input_tokens/pricing_units) * input_rate
output_cost = (output_tokens/pricing_units) * output_rate
return input_cost + output_cost
def get_response_model(response):
return response.model
def get_response_tokens(response):
return response.usage.prompt_tokens, response.usage.completion_tokens
def get_response_content(response):
return response.choices[0].message.content
def get_response_metadata(response, verbose=True):
model = get_response_model(response)
input_tokens, output_tokens = get_response_tokens(response)
cost = get_response_cost(response)
return model, (input_tokens, output_tokens), cost
The above code will create a back and forth conversation you can continue in your browser, but if you just want to experiment with a back and forth model in a Jupyter Notebook you can do that very easily just with two blocks at X lines of code (could actually be much smaller but I added extra functionality to record conversation metadata and verbosily defined messages and model opetions etc. All you have to do is add your OPENAI_API_KEY to your system variables and then run code block 1, and then repeatedly run code block 2 to continue the conversation, updating the next_message variable each time.
# code block 1
# imports
import os
from datetime import datetime
from openai import OpenAI
# define model and response options
model = 'gpt-4o'
max_tokens = 2**8
temperature = 1
n_responses = 1
# define system prompt
system_prompt = 'You are a helpful AI assistant.'
# provide initial user message
user_prompt = 'What is San Fransisco like in the summer?'
# create OpenAI client using your OPENAI_API_KEY stored in your system variables
client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
# create dictionary to store conversation meta-data
conversation_metadata = {
'start_time': None,
'n_user_messages': 0,
'n_assistant_messages': 0,
'n_input_tokens': 0,
'n_output_tokens': 0
}
# create list of messages
messages = []
messages.append(
{
'role': 'system',
'content': system_prompt
}
)
messages.append(
{
'role': 'user',
'content': user_prompt
}
)
# define call_client function to pass messages and model parameters to API, and update the converstaion_metadata
def call_client(messages, conversation_metadata, model=model, n_responses=n_responses, max_tokens=max_tokens, temperature=temperature):
t0 = datetime.now()
if not conversation_metadata['start_time']:
conversation_metadata['start_time'] = t0
response = client.chat.completions.create(
model=model,
messages=messages,
n=n_responses,
max_tokens=max_tokens,
response_format={'type': 'text'},
temperature=temperature
)
conversation_metadata['n_input_tokens'] = response.usage.prompt_tokens
conversation_metadata['n_output_tokens'] += response.usage.completion_tokens
return response, conversation_metadata
# define helper function to print conversation metadata
def print_conversation_metadata(conversation_metadata, response, verbose=False):
print('Most recent response data')
print(f'Number of prompt tokens: {response.usage.prompt_tokens}')
print(f'Number of completion tokens: {response.usage.completion_tokens}')
if verbose:
print(f'Entire most recent response: \n {response.choices[0].message.content[:]}')
else:
print(f'First 100 characters of most recent response: \n {response.choices[0].message.content[:100]}')
print('\nConversation metadata data')
print(f'Conversation began at: {conversation_metadata['start_time']}')
print(f'Number of prompt tokens: {conversation_metadata['n_input_tokens']}')
print(f'Number of prompt tokens: {conversation_metadata['n_output_tokens']}')
return
# perform API call and print conversation metadata
response, conversation_metadata = call_client(messages, conversation_metadata)
print_conversation_metadata(conversation_metadata, response, verbose=False)
# code block 2
# define subsequent message
next_message = 'What was my last message?'
# append previous assistant response and current user message to messages
messages.append(
{
'role': 'assistant',
'content': response.choices[0].message.content
}
)
messages.append(
{
'role': 'user',
'content': next_message
}
)
# perform API call and print conversation metadata
response, conversation_metadata = call_client(messages, conversation_metadata)
print_conversation_metadata(conversation_metadata, response, verbose=True)
To make your OPENAI_API_KEY available in your environment, create and copy your api key from https://platform.openai.com/api-keys to your .zshrc file (if you are on MacOS), which is typically stored at ~/.zshrc using the format:
export KAGGLE_KEY='[YOUR OPENAI_API_KEY_HERE]'
and then run source ~/.zshrc to initialise the updated environment.